Forward Deployment Engineering for Platform Engineering: Building Your Internal Developer Platform Without Distracting Product Teams
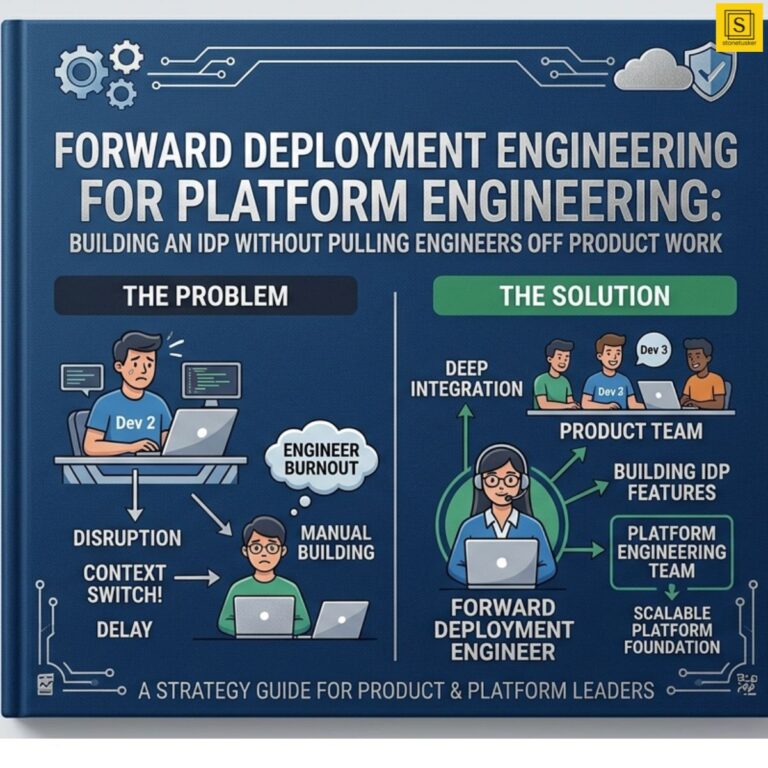
The internal developer platform your teams need usually cannot be built by the same engineers already responsible for shipping customer features.
That constraint sits at the centre of many stalled platform engineering programmes.
Leadership teams recognise the need for standardised CI/CD workflows, self-service infrastructure provisioning, Kubernetes abstractions, deployment automation, developer onboarding improvements, and operational consistency. The engineering organisation clearly needs a platform layer.
But the same senior engineers required to build that platform are also the engineers responsible for delivering revenue-generating product work.
In practice, product deadlines win almost every prioritisation conflict.
The result is predictable.
Platform engineering becomes fragmented side work. Internal tooling evolves inconsistently. Developer experience deteriorates slowly across teams. Infrastructure standards diverge. Delivery bottlenecks increase. Engineering leaders continue discussing platform modernisation every quarter without creating sustained implementation momentum.
This is one of the reasons Forward Deployment Engineering has become increasingly relevant for platform engineering initiatives.
Instead of attempting to pause product delivery to build internal platforms, organisations embed specialised implementation engineers alongside internal teams to accelerate platform delivery while product teams continue shipping.
The engagement model changes the economics of platform engineering.
The Hidden Cost of Building an Internal Developer Platform Internally
Most platform engineering discussions focus heavily on tooling.
Teams debate Backstage, Kubernetes abstractions, GitOps tooling, IaC frameworks, CI/CD orchestration layers, observability stacks, developer portals, and workflow automation.
The harder problem is usually organisational bandwidth.
Internal developer platforms require some of the organisation’s strongest engineers because the work spans:
- Infrastructure architecture.
- Developer workflow design.
- Release engineering.
- Security integration.
- CI/CD standardisation.
- Operational automation.
- Cross-team enablement.
- Kubernetes operations.
- Developer experience design.
Unfortunately, those same engineers are often deeply embedded inside critical product delivery streams.
When organisations redirect senior product engineers toward internal platform initiatives, several things happen simultaneously:
- Feature delivery slows across roadmap-critical products.
- Architectural decision-making weakens inside product teams.
- Incident response capacity becomes thinner.
- Release velocity decreases temporarily.
- Technical debt reduction programmes pause.
- Platform delivery still progresses slower than expected because engineers remain context-switched.
The opportunity cost becomes substantial.
Many organisations underestimate how disruptive platform engineering work can become when treated as a part-time responsibility.
Platform engineering is not just another backlog item. It is effectively a parallel product organisation operating inside the engineering function.
Measure Your Platform Engineering Readiness Before Starting an IDP Initiative
Many platform modernisation programmes struggle because organisations attempt implementation before understanding delivery maturity, operational fragmentation, and engineering workflow bottlenecks.
Use TuskerGauge to assess your engineering delivery maturity before planning platform engineering investments.
Why Internal Developer Platforms Fail to Gain Adoption
Even technically competent platform initiatives frequently fail operationally.
The failure usually comes from implementation dynamics rather than tooling limitations.
Common failure patterns include:
Platform Teams Become Ticket Queues
Instead of building scalable abstractions and self-service workflows, internal platform teams spend most of their time handling infrastructure requests manually.
This creates another operational dependency layer rather than reducing engineering friction.
Developer Workflows Are Designed Without Developer Input
Many platforms prioritise governance and infrastructure standardisation while neglecting usability.
The 2024 DORA report reinforced the importance of user-centric platform engineering approaches and highlighted that platform adoption improves organisational performance only when developer experience remains central to implementation decisions. :contentReference[oaicite:1]{index=1}
Product Engineers Do Not Trust the Platform
If migration workflows are painful or deployment abstractions feel restrictive, teams bypass the platform entirely.
Shadow tooling emerges quickly inside engineering organisations.
Migration Programmes Never Finish
Most organisations underestimate the operational migration work required after platform foundations exist.
Standardising CI/CD pipelines, deployment patterns, observability baselines, infrastructure templates, and service onboarding processes across dozens or hundreds of repositories requires sustained execution effort.
The Structural Problem With Internal-Only Platform Engineering
The deeper issue is usually execution capacity.
Leadership expects platform engineering to improve engineering velocity, but the implementation itself consumes the exact engineering capacity already under pressure.
This creates a structural contradiction:
The organisation needs a platform because engineering teams are overloaded, but building the platform overloads the engineering teams further.
This is where Forward Deployment Engineering changes the model.
What Forward Deployment Engineering Looks Like in Platform Engineering
Forward Deployment Engineering originated from implementation-heavy software delivery environments where customers needed embedded technical specialists capable of operational execution, not just advisory consulting.
Inside platform engineering programmes, Forward Deployment Engineers typically operate as embedded implementation partners.
They work directly alongside internal teams to:
- Design internal platform architecture.
- Standardise CI/CD workflows.
- Implement Kubernetes operational abstractions.
- Create golden deployment paths.
- Build Infrastructure as Code templates.
- Improve developer onboarding workflows.
- Implement observability standards.
- Automate environment provisioning.
- Operationalise security controls inside delivery pipelines.
- Reduce deployment friction across engineering teams.
The key distinction is operational ownership.
Traditional consulting engagements often stop at recommendations and architecture diagrams.
Forward Deployment Engineering focuses on implementation execution inside the customer environment.
The external specialists help carry delivery load directly rather than adding additional advisory overhead.
Why This Model Protects Product Delivery Velocity
The largest benefit is not purely technical.
It is organisational.
Forward Deployment Engineering allows product engineering teams to maintain focus on customer-facing delivery while specialised implementation engineers accelerate platform modernisation work in parallel.
Internal engineers still participate heavily in architectural decisions, operational reviews, and workflow validation, but they are no longer solely responsible for driving every implementation stream.
This reduces several common platform engineering risks:
- Roadmap disruption becomes more manageable.
- Platform initiatives maintain implementation momentum.
- Migration work progresses continuously.
- Senior engineers avoid permanent context switching.
- Operational standardisation happens faster.
- Internal teams gain implementation knowledge through direct collaboration.
The model works particularly well when platform initiatives require immediate operational acceleration but internal hiring timelines remain slow.
Many organisations cannot recruit experienced platform engineers quickly enough to match transformation timelines.
Embedded Forward Deployment Engineers create temporary implementation capacity without permanently expanding organisational overhead.
Typical Outcomes Teams Measure After Implementation
- Engineering teams often reduce deployment rollback frequency after standardising release automation workflows.
- Platform teams commonly improve infrastructure consistency after implementing infrastructure-as-code provisioning pipelines.
- Engineering organisations usually improve deployment visibility after consolidating fragmented observability tooling.
- Developer onboarding workflows frequently become faster after standardising environment provisioning and deployment templates.
- Platform adoption rates often improve when engineering teams receive embedded migration support instead of centralised documentation-only rollouts.
The Most Effective Forward Deployment Engagement Pattern
The strongest platform engineering engagements rarely begin with tooling selection.
They usually begin with workflow analysis.
Experienced Forward Deployment Engineers typically examine:
- Deployment bottlenecks.
- Developer onboarding friction.
- Release coordination overhead.
- Environment inconsistency.
- Infrastructure provisioning delays.
- CI/CD fragmentation.
- Kubernetes operational complexity.
- Observability gaps.
- Developer experience pain points.
- Cross-team workflow variance.
Only after understanding operational friction does platform architecture become meaningful.
This matters because many internal developer platforms fail by becoming infrastructure-centric rather than workflow-centric.
Developers adopt platforms that remove operational friction.
They avoid platforms that merely centralise governance.
The DORA Research Around Platform Engineering Supports This Reality
The 2024 DORA research highlighted that internal developer platforms improve developer productivity and organisational performance when implemented thoughtfully. However, the report also identified temporary throughput and stability challenges during platform adoption and maturation phases. :contentReference[oaicite:2]{index=2}
That finding aligns closely with real-world platform implementation behaviour.
Most platform engineering programmes experience three distinct phases:
Phase 1: Initial Acceleration
Early standardisation creates immediate operational improvements.
Teams often experience deployment consistency gains quickly.
Phase 2: Organisational Friction
Migration complexity emerges.
Legacy workflows resist standardisation.
Product teams question migration overhead.
Operational edge cases increase.
Phase 3: Platform Maturity
Once adoption patterns stabilise and workflows mature, engineering organisations begin realising broader developer productivity and operational consistency improvements.
The challenge is surviving Phase 2 without exhausting internal engineering capacity.
This is exactly where embedded Forward Deployment support becomes valuable.
Discuss Your Platform Bottlenecks With an Engineering Specialist
Many platform engineering problems are organisational execution problems rather than tooling problems.
Discuss your deployment and platform bottlenecks with a Stonetusker Systems engineer to evaluate whether embedded implementation support fits your delivery model.
What Strong Platform-Focused Forward Deployment Engineers Actually Bring
Effective Forward Deployment Engineers combine several operational capabilities simultaneously.
Implementation Experience
They have usually worked directly inside complex delivery environments rather than purely advisory roles.
That operational experience matters during migration and standardisation work.
Cross-Domain Platform Understanding
Internal developer platforms sit across infrastructure, developer workflows, CI/CD, Kubernetes operations, security, release engineering, and observability.
Specialists need practical understanding across those operational layers.
Embedded Collaboration Behaviour
The engagement succeeds only when external engineers integrate naturally into existing engineering workflows.
This is not a detached consulting exercise.
The work happens inside delivery systems alongside product and infrastructure teams.
Operational Pragmatism
Mature platform engineers understand that platform standardisation is always constrained by legacy systems, team autonomy, migration fatigue, compliance requirements, and roadmap pressure.
Strong implementation specialists avoid idealised platform architectures disconnected from operational reality.
Trade-Offs Organisations Should Understand Before Starting
Forward Deployment Engineering is not a shortcut around organisational complexity.
Several trade-offs remain important.
Internal Ownership Still Matters
External implementation support cannot compensate for absent internal platform ownership.
Leadership alignment and platform governance still require internal accountability.
Migration Fatigue Is Real
Even well-designed platforms create temporary migration overhead for product teams.
Engineering organisations need realistic rollout sequencing.
Not Every Workflow Should Be Standardised
Over-centralised platforms often reduce developer flexibility.
Strong platform engineering focuses on reducing unnecessary variation without eliminating engineering autonomy.
Platform Product Thinking Is Essential
The platform must behave like a product serving internal engineering users.
Developer adoption becomes the real success metric.
Operational elegance alone is insufficient.
The Real Strategic Advantage
The strongest organisations eventually recognise that platform engineering is not fundamentally an infrastructure initiative.
It is an engineering throughput initiative.
The objective is not merely creating another internal platform layer.
The objective is reducing friction inside software delivery systems.
That includes:
- Reducing deployment coordination overhead.
- Improving release consistency.
- Accelerating onboarding.
- Reducing operational cognitive load.
- Improving engineering focus.
- Reducing workflow fragmentation.
- Improving delivery reliability.
- Creating scalable engineering standards.
DORA research continues showing strong correlations between mature engineering practices, developer productivity, and operational performance. :contentReference[oaicite:3]{index=3}
But those improvements require sustained implementation capacity.
That is the execution gap many organisations struggle to solve internally.
FAQ
Why do internal developer platform initiatives often stall?
Most platform initiatives stall because the same senior engineers responsible for product delivery are also expected to drive platform implementation. Product roadmap commitments usually take priority, causing platform work to become fragmented and inconsistent. Over time, migration work slows, adoption weakens, and platform teams become reactive support functions rather than strategic engineering enablement teams.
What does a Forward Deployment Engineer do during a platform engagement?
Forward Deployment Engineers operate as embedded implementation specialists working directly inside the customer engineering environment. They help design platform architecture, implement CI/CD standardisation, operationalise Kubernetes workflows, automate infrastructure provisioning, support migration efforts, and improve developer experience while collaborating closely with internal engineering teams.
Does this approach create dependency on external engineers?
Strong engagements are usually structured around capability transfer rather than permanent dependency. Internal engineering teams retain architectural ownership and operational control while embedded specialists accelerate implementation and migration work. The long-term goal is normally platform maturity and internal operational sustainability rather than outsourcing core engineering capability.
Which organisations benefit most from this model?
The model works especially well for organisations experiencing rapid engineering growth, platform fragmentation, CI/CD inconsistency, Kubernetes operational complexity, onboarding friction, or delivery bottlenecks across multiple teams. It is particularly effective when platform modernisation urgency exceeds current internal implementation capacity.
How long do platform-focused Forward Deployment engagements usually last?
Engagement timelines vary significantly depending on platform maturity, migration complexity, organisational alignment, and operational scope. Some focused standardisation programmes may run for several weeks, while broader internal developer platform initiatives can extend across multiple quarters. The objective is usually establishing scalable workflows and operational foundations rather than permanent embedded staffing.
Conclusion
Most internal developer platform initiatives do not fail because organisations choose the wrong tooling.
They fail because implementation capacity never matches platform ambition.
Engineering leaders attempt to modernise delivery systems using engineers already overloaded with product commitments, operational support, release coordination, and roadmap pressure.
The result is predictable platform stagnation.
Forward Deployment Engineering changes the execution model.
Instead of forcing platform engineering and product engineering to compete for the same internal bandwidth, organisations introduce embedded implementation specialists who accelerate platform delivery while product teams continue shipping.
That separation matters operationally.
Because the internal developer platform your teams need usually cannot be built effectively by engineers already consumed by customer roadmap delivery.
Discuss Your Platform Engineering Delivery Constraints
If your organisation is struggling to build platform capability without slowing product delivery, an embedded implementation model may help accelerate standardisation while protecting engineering throughput.
Discuss your engineering delivery challenges with a Forward Deployment specialist.
Further Reading
- DORA Accelerate State of DevOps Report 2024
- Google Cloud DORA Research Summary
- Platform Engineering Community
- Backstage Developer Portal
- Kubernetes Documentation
- Cloud Native Computing Foundation
About the Author
Subeesh Sivanandan is Founder and CEO of Stonetusker Systems with 26 years of experience across DevOps, CI/CD, platform engineering, release engineering, infrastructure automation, and engineering transformation programmes.
He has worked with organisations including Stryker, Nokia, IP Infusion, and VeriSign, helping engineering teams improve delivery reliability, platform scalability, and operational automation across enterprise and regulated environments.

