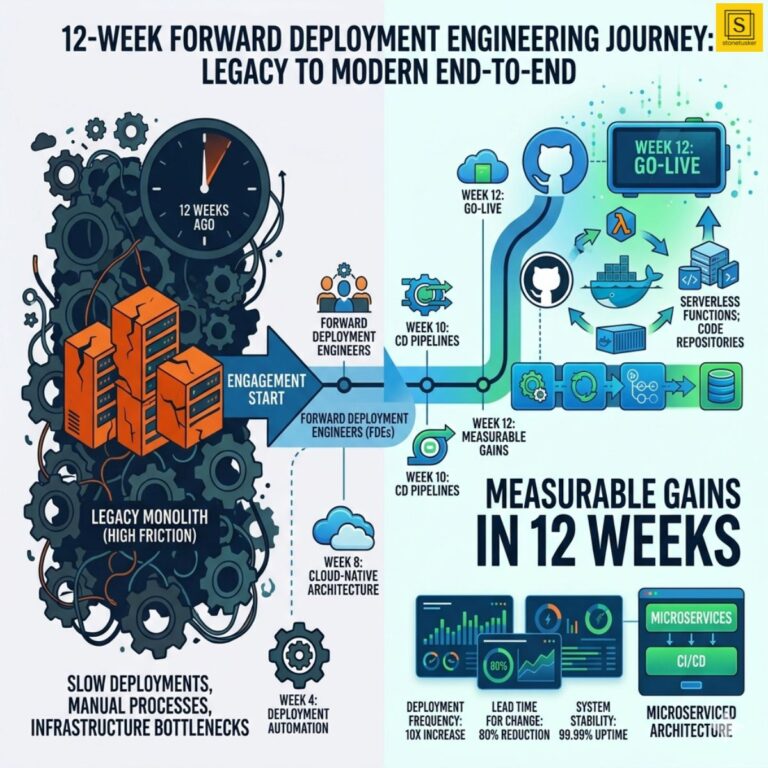
The 90-Day Forward Deployment Engagement: What Realistic Progress Looks Like Week by Week
A 90-day forward deployment engagement is not enough time to transform everything.
It is enough time to transform one critical system completely and build the operational capability to continue.
That distinction matters.
Many engineering leaders approach short implementation engagements with two competing fears. One is that consultants will spend three months producing assessments, architecture diagrams, and recommendations without changing anything operationally meaningful. The other is that the engagement promises unrealistic organisation-wide transformation within a timeframe that simply does not support it.
Both concerns are valid.
The most effective Forward Deployment Engineering engagements avoid both extremes. They focus on one operationally important bottleneck, modernise it deeply, leave behind working systems and repeatable engineering practices, and help internal teams continue the work independently afterwards.
This article breaks down what realistic progress usually looks like week by week during a 90-day Forward Deployment Engineering engagement.
Assess Your Delivery Maturity Before Planning Modernisation
Many engineering bottlenecks look like tooling problems when they are actually workflow and operational design problems. Assessing deployment maturity early helps teams prioritise the right systems first.
Use TuskerGauge to evaluate your engineering delivery maturity
What a Forward Deployment Engagement Actually Is
A Forward Deployment Engineering engagement is fundamentally an embedded implementation model.
The goal is not simply advisory consulting.
The engagement team works directly inside engineering workflows alongside platform teams, developers, infrastructure engineers, security teams, and engineering leadership to modernise a specific operational area.
Typical focus areas include:
- CI/CD pipeline modernisation.
- Kubernetes deployment standardisation.
- Infrastructure automation.
- Release engineering stabilisation.
- Developer platform implementation.
- Deployment reliability improvement.
- Observability integration.
- DevSecOps workflow implementation.
- Environment provisioning automation.
The engagement usually succeeds or fails based on scope discipline.
Teams that attempt to modernise everything simultaneously often spread engineering attention too thinly. Progress becomes difficult to measure. Stakeholder confidence drops quickly.
The strongest engagements instead choose one system with measurable operational pain and solve it properly.
What Realistic Success Looks Like After 90 Days
By the end of a strong 90-day engagement, organisations commonly achieve:
- A fully operational modernised workflow for one high-impact engineering system.
- Production-tested automation rather than proof-of-concept tooling.
- Standardised deployment or infrastructure patterns.
- Improved visibility into deployment health and operational failures.
- Reduced manual engineering overhead.
- Documented operational practices and implementation standards.
- Internal engineering ownership of the resulting systems.
What usually does not happen within 90 days:
- Complete enterprise-wide engineering transformation.
- Total platform standardisation across all teams.
- Elimination of technical debt.
- Complete cultural transformation.
- Organisation-wide process alignment.
Those efforts typically require longer operational programmes.
Weeks 1-2: Discovery, Baseline, and Constraint Mapping
The first two weeks are usually less glamorous than many stakeholders expect.
This phase is heavily focused on understanding operational reality.
Forward Deployment Engineers spend time analysing:
- Current deployment workflows.
- Release bottlenecks.
- Pipeline failure patterns.
- Manual operational dependencies.
- Infrastructure inconsistencies.
- Security constraints.
- Approval processes.
- Developer workflow friction.
- Production incident patterns.
This phase often exposes uncomfortable truths.
Engineering leadership may believe the problem is tooling while the real issue is fragmented ownership. Platform teams may blame developers while the underlying issue is inconsistent environment provisioning. Security teams may appear to slow releases when the deeper problem is missing automation and policy integration.
Strong engagements establish a measurable baseline early.
That usually includes metrics such as:
- Deployment frequency.
- Pipeline execution duration.
- Rollback frequency.
- Change failure rate.
- Mean time to recovery.
- Manual approval delays.
- Infrastructure provisioning lead times.
The 2024 Google Cloud DORA research continues to show strong correlation between engineering delivery performance, deployment automation, and organisational delivery capability. High-performing teams consistently demonstrate lower recovery times and higher deployment reliability.
The early discovery phase also identifies political and organisational constraints that often matter more than technology itself.
That includes:
- Teams protecting existing workflows.
- Legacy ownership disputes.
- Tooling fragmentation.
- Conflicting engineering priorities.
- Compliance restrictions.
- Procurement delays.
- Skill gaps inside platform teams.
Ignoring those realities early almost always creates implementation problems later.
Weeks 3-4: Architecture Decisions and Scope Locking
Weeks three and four usually determine whether the engagement stays realistic.
This is where implementation scope gets narrowed aggressively.
Experienced Forward Deployment teams intentionally reduce ambition at this stage. That may sound counterintuitive, but it is operationally necessary.
Most engineering organisations discover far more improvement opportunities during discovery than can realistically be delivered within 90 days.
Good scope decisions prioritise:
- Systems creating the highest operational drag.
- Workflows with measurable engineering impact.
- Areas where automation can remove repetitive operational work.
- Systems with achievable adoption paths.
- Infrastructure where implementation dependencies are manageable.
During this phase, engineering teams usually finalise:
- Reference architectures.
- Toolchain decisions.
- Infrastructure patterns.
- Deployment strategies.
- Rollout sequencing.
- Security integration requirements.
- Ownership boundaries.
This stage often involves difficult trade-offs.
For example:
- Should the engagement modernise an existing CI/CD platform or replace it entirely?
- Should Kubernetes standardisation happen before observability integration?
- Should infrastructure automation prioritise speed or compliance controls initially?
- Should deployment workflows optimise for developer flexibility or operational consistency?
These are not purely technical decisions.
They affect long-term maintainability, adoption friction, and operational ownership.
Typical Outcomes Teams Measure After Implementation
- Engineering teams often reduce deployment rollback frequency after standardising release automation workflows.
- Platform teams commonly improve infrastructure consistency after implementing infrastructure-as-code provisioning pipelines.
- Engineering organisations usually improve deployment visibility after consolidating fragmented observability tooling.
Weeks 5-6: Core Implementation Begins
This is where the engagement becomes visibly operational.
Implementation work typically accelerates rapidly during weeks five and six because discovery and architecture decisions have already removed major ambiguity.
Depending on the engagement scope, implementation may include:
- CI/CD pipeline redesign.
- Infrastructure-as-code implementation.
- GitOps workflow integration.
- Deployment orchestration.
- Observability instrumentation.
- Kubernetes environment standardisation.
- Policy automation.
- Secrets management integration.
- Automated testing integration.
This stage usually exposes hidden operational debt.
Examples include:
- Undocumented deployment dependencies.
- Environment drift.
- Manual scripts nobody owns.
- Legacy authentication integrations.
- Inconsistent container standards.
- Broken rollback procedures.
- Unmaintained infrastructure modules.
Most organisations underestimate how much invisible operational complexity accumulates over years of incremental delivery.
That complexity becomes highly visible during automation work.
Discuss Delivery Bottlenecks With an Engineer
Many engineering teams already know where operational friction exists. The difficult part is prioritising which system to modernise first without disrupting active delivery.
Discuss your deployment and platform engineering constraints with Stonetusker Systems
Weeks 7-8: Stabilisation and Operational Hardening
This phase is frequently underestimated.
Building automation is usually faster than stabilising it.
By weeks seven and eight, most core implementation work exists in functional form. The focus shifts toward reliability, operational edge cases, and production readiness.
Engineering teams often spend significant time addressing:
- Deployment rollback behaviour.
- Pipeline concurrency issues.
- Access control edge cases.
- Observability gaps.
- Security scanning noise.
- Performance bottlenecks.
- Secrets rotation behaviour.
- Production environment parity problems.
This is also where internal engineering confidence starts changing materially.
Early scepticism often declines once teams see working systems rather than architectural proposals.
One of the most important signals during this phase is whether engineers voluntarily start adopting the new workflows outside the immediate implementation scope.
That usually indicates the engagement solved a real operational problem rather than introducing additional process overhead.
Weeks 9-10: Team Enablement and Workflow Adoption
Many engineering transformation efforts fail because implementation happens without operational adoption.
Weeks nine and ten focus heavily on ensuring the internal engineering organisation can operate independently after the engagement ends.
This phase commonly includes:
- Developer onboarding sessions.
- Platform operations walkthroughs.
- Runbook creation.
- Incident response integration.
- Operational documentation.
- Infrastructure ownership transfer.
- Security review processes.
- Release workflow training.
Good Forward Deployment Engineers deliberately avoid becoming permanent operational dependencies.
The goal is capability transfer, not consultant dependency.
This phase also reveals adoption friction that technical implementation alone cannot solve.
Examples include:
- Developers bypassing new workflows.
- Teams resisting standardisation.
- Competing internal tooling preferences.
- Legacy release exceptions.
- Unclear ownership boundaries.
Operational modernisation almost always includes behavioural change.
That does not happen automatically because automation exists.
Weeks 11-12: Handover, Metrics Review, and Expansion Planning
The final weeks are less about finishing work and more about making the improvements sustainable.
Strong engagements end with:
- Operational ownership clearly assigned.
- Deployment workflows documented.
- Infrastructure standards established.
- Rollback procedures tested.
- Observability integrated.
- Known limitations documented.
- Future modernisation priorities identified.
This is also where leadership reviews measurable operational outcomes against the original baseline.
That comparison matters.
Without measurable before-and-after visibility, engineering modernisation discussions become subjective very quickly.
Common measurable improvements include:
- Reduced deployment lead times.
- Lower manual operational effort.
- Faster rollback execution.
- Improved deployment visibility.
- Reduced environment inconsistency.
- More predictable release behaviour.
Importantly, most organisations leave the engagement with a clearer understanding of what still remains unresolved.
That is healthy.
Good implementation work exposes the next layer of operational bottlenecks.
What Usually Goes Wrong in 90-Day Engagements
Several patterns repeatedly create problems during short implementation engagements.
Trying to Modernise Too Much
This is the most common failure pattern.
Leadership often wants infrastructure modernisation, CI/CD replacement, observability rollout, Kubernetes migration, and security integration simultaneously.
That scope almost always exceeds realistic implementation capacity.
Insufficient Internal Ownership
Forward Deployment Engineering works best when internal platform and engineering teams remain deeply involved throughout implementation.
Consultants cannot sustainably own operational systems after the engagement ends.
Ignoring Organisational Constraints
Engineering modernisation is rarely blocked only by technology.
Approval structures, security processes, fragmented ownership, and delivery pressure often create larger implementation constraints than tooling itself.
Over-Engineering the Initial System
Some engagements spend too much time designing theoretically perfect platforms instead of delivering practical operational improvements quickly.
Simplicity usually improves adoption.
How to Evaluate Whether a 90-Day Engagement Worked
Strong engagements usually produce evidence in four areas.
Operational Evidence
- Working production systems exist.
- Automation replaces manual engineering effort.
- Deployment reliability improves measurably.
- Engineering workflows become more consistent.
Organisational Evidence
- Teams voluntarily adopt the workflows.
- Ownership boundaries become clearer.
- Engineering coordination improves.
- Operational friction decreases.
Technical Evidence
- Infrastructure standardisation improves.
- Observability coverage increases.
- Deployment processes become repeatable.
- Rollback behaviour becomes predictable.
Strategic Evidence
- Leadership understands future modernisation priorities more clearly.
- The engineering organisation gains reusable implementation patterns.
- Future platform investments become easier to prioritise.
The Most Realistic Outcome of a Good Engagement
The most successful 90-day engagements rarely “finish transformation”.
Instead, they create momentum.
They prove that one painful engineering workflow can actually become reliable, automated, observable, and maintainable.
That changes internal confidence significantly.
Once engineering teams experience a genuinely functional delivery workflow, broader modernisation efforts become easier to justify operationally.
The organisation also gains something more valuable than tooling alone.
It gains implementation patterns, operational lessons, and internal capability.
Planning a Forward Deployment Engagement?
If your engineering organisation is struggling with deployment bottlenecks, infrastructure inconsistency, or fragmented platform operations, a focused Forward Deployment engagement can modernise one critical system deeply enough to create measurable operational progress.
Discuss your engineering delivery challenges with a Forward Deployment specialist
Frequently Asked Questions
Is 90 days enough time for meaningful engineering transformation?
Ninety days is usually enough time to fully modernise one critical engineering workflow or operational subsystem. It is generally not enough time to transform an entire engineering organisation. The strongest engagements focus on solving one high-impact bottleneck properly, then leave behind reusable implementation patterns and internal operational capability for broader modernisation afterwards.
What systems are typically prioritised during a Forward Deployment Engineering engagement?
Most engagements focus on systems causing operational instability, release delays, deployment inconsistency, or excessive manual engineering work. Common priorities include CI/CD modernisation, Kubernetes deployment workflows, infrastructure automation, release engineering stabilisation, observability integration, and platform engineering standardisation.
How involved does the internal engineering team need to be?
Internal engineering participation is essential. Forward Deployment Engineering is most effective when platform teams, developers, security engineers, and infrastructure teams work collaboratively throughout discovery, implementation, rollout planning, and operational handover. Organisations that treat the engagement as outsourced delivery often struggle with long-term adoption afterwards.
What happens after the 90-day engagement ends?
Most organisations continue broader modernisation work internally after the engagement concludes. The engagement should leave behind working operational systems, automation patterns, documentation, standards, and engineering ownership that allow teams to continue improving delivery workflows independently.
What are the biggest risks during a short engineering transformation engagement?
The biggest risks usually include unrealistic scope expansion, fragmented ownership, insufficient engineering participation, leadership misalignment, and attempting to modernise multiple unrelated systems simultaneously. Short engagements work best when the implementation target remains tightly prioritised and operationally measurable.
Conclusion
A realistic 90-day Forward Deployment Engineering engagement does not promise complete organisational transformation.
It focuses on solving one important operational problem thoroughly enough that engineering teams can feel the difference in daily delivery work.
That may be a deployment workflow that no longer breaks every week. It may be infrastructure provisioning that finally becomes predictable. It may be release engineering that stops depending on tribal knowledge and manual intervention.
The measurable outcome is not usually “transformation”.
The measurable outcome is operational confidence.
And in most engineering organisations, that is where meaningful modernisation actually begins.
Further Reading
- Google Cloud DORA State of DevOps Reports
- Kubernetes Official Documentation
- OpenTelemetry Documentation
- Terraform Documentation
- Martin Fowler on Continuous Delivery
- OWASP DevSecOps Guidelines
About the Author
Subeesh Sivanandan is Founder and CEO of Stonetusker Systems with 26 years of experience across DevOps, CI/CD, platform engineering, release engineering, infrastructure automation, and engineering transformation programmes.
He has worked with organisations including Stryker, Nokia, IP Infusion, and VeriSign, helping engineering teams improve delivery reliability, platform scalability, and operational automation across enterprise and regulated environments.

